





Abstract
The success of community projects such as Wikipedia has recently prompted a discussion about the applicability of such tools in the life sciences. Currently, there are several such ‘science-wikis’ that aim to collect specialist knowledge from the community into centralized resources. However, there is no consensus about how to achieve this goal. For example, it is not clear how to best integrate data from established, centralized databases with that provided by ‘community annotation’. We created PDBWiki, a scientific wiki for the community annotation of protein structures. The wiki consists of one structured page for each entry in the the Protein Data Bank (PDB) and allows the user to attach categorized comments to the entries. Additionally, each page includes a user editable list of cross-references to external resources. As in a database, it is possible to produce tabular reports and ‘structure galleries’ based on user-defined queries or lists of entries. PDBWiki runs in parallel to the PDB, separating original database content from user annotations. PDBWiki demonstrates how collaboration features can be integrated with primary data from a biological database. It can be used as a system for better understanding how to capture community knowledge in the biological sciences. For users of the PDB, PDBWiki provides a bug-tracker, discussion forum and community annotation system. To date, user participation has been modest, but is increasing. The user editable cross-references section has proven popular, with the number of linked resources more than doubling from 17 originally to 39 today.
Database URL: http://www.pdbwiki.org
Introduction
The number of protein structures deposited in the Protein Data Bank (PDB) (1) has recently surpassed 60 000 and continues to grow at an increasing rate (2, 3). The PDB was one of the first central repositories of biological experimental data and has enabled progress in many areas of structural biology. The atomic resolution data in the PDB is the basis for the analysis of enzyme catalysis (4–6), the study of protein folding (7) and the evolution of protein structure (8–10). Protein structure prediction, for example, has lead to functional insights with direct bearing on human health and disease (11).
The PDB provides a primary source of protein structure reference data for the community. Its central importance is reflected in the number of derived databases that stem from and augment the central archive (see http://pdbwiki.org/index.php/Template:PDB_search). However, for most protein structure studies, it is not feasible to create a ‘database’ of annotations to present the findings. Therefore, the results of most studies are typically only found in the literature. For this reason, much of the information about the structures in the PDB cannot be easily integrated back into the central archive.
Although centrally controlled databases of biological data have proven crucially important for research, growth in the volume of data has led to several problems. The data they contain are often static, not permitting user-contributed edits. This means that changes to the data must be coordinated by typically just a few database curators, and annotations are prone to becoming out of date as new algorithms are developed and new discoveries are made. Similarly, known errors may go uncorrected and special cases in the data may not be deposited adequately. These problems emphasize the growing need for usable community annotation databases.
Scientific wikis have the potential to allow for the community annotation of important biological data (12–14). Such projects aim to integrate specialist knowledge from many disparate groups of researchers, ensuring annotations are accurate and up-to-date. Currently, several such projects exist, either based within Wikipedia (15, 16) or on distinct wikis (17–19). Although there is clearly considerable interest in developing such community annotation systems, there is no general consensus about how best to combine the strengths of community annotation with those of more traditional biological databases (20–23).
Here, we present a new scientific wiki that addresses some of the issues described above. PDBWiki is a system for the annotation of the protein structures deposited in the PDB (1). The system combines a large, static database of heterogeneous biological data with a wiki system for community annotation. The resulting database can serve as a bug-tracker and discussion forum for the structures in the PDB. The database runs in parallel to the central archive, and incorporates user comments in a semi-structured way, allowing for the possibility of incorporating annotations back into the PDB.
Methods
PDBWiki has been implemented using MediaWiki http://www.mediawiki.org, the same software that runs Wikipedia. MediaWiki provides a very stable framework that allowed us to create a very large set of pages with many inbuilt features for community annotation.
Briefly, some of the key features of MediaWiki include the following. ‘Versioning’, every edit made to a page is stored and can be reviewed at any time. Previous versions can be easily reviewed or recovered. ‘Notifications’, pages of interest to the user can be added to a ‘watch-list’, whereby they are automatically notified of all changes by email or RSS. ‘Transparency’, any change to the data in the wiki can be tracked, and the user responsible for a given change can be identified.
Our MediaWiki installation has been extended with several standard and two newly developed extensions. The first new extension provides the ‘user comments’ form that is used on each PDB entry page. The second new extension adjusts the default image functionality of the wiki to manage the image provided for each PDB entry. Among the standard extensions, we use the Dynamic Page List extension http://semeb.com/dpldemo/index.php?title=Dynamic_Page_List, to generate the structured reports.
Data from the PDB is automatically synchronized with PDBWiki every week. In summary, new PDB entries are added as new pages, updated entries are recreated and obsolete entries are ‘retired’. User comments for obsolete entries remain in the system and are automatically linked to the updated PDB entry (where applicable).
To facilitate the update process, we use the OpenMMS software package http://openmms.sdsc.edu to create a relational database from the data in the PDB. Building the relational database from the complete set of entries in the PDB takes roughly 24 h. Using this relational database, we collect the data needed to update PDBWiki using a series of SQL queries. Finally, the wiki is updated using the Python Wikipedia Robot framework http://pywikipediabot.sourceforge.net.
All the source code developed as part of the PDBWiki project has been made available in an open source project repository, hosted by The Bioinformatics Organization (http://Bioinformatics.Org/project/?group_id=936).
The article has been written collaboratively using a separate MediaWiki installation.
Results
Overview
PDBWiki is centered around the macromolecular structures deposited into the PDB. Each structure in the PDB has a separate page in the wiki, giving a total of over 60 000 structure pages. A structure page is split into three main sections: data, user comments and links (Figure 1). The three main sections are described in the following three paragraphs.
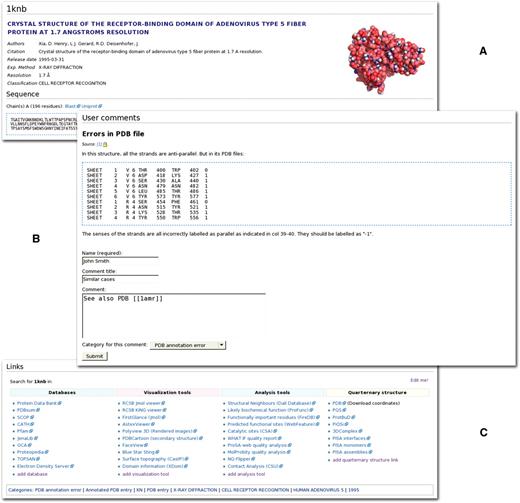
A typical PDBWiki ‘structure page’. There is one structure page for each structure in the Protein Data Bank, with three main sections; data (A), user comments (B) and links (C). See the Overview section of the ‘Results’ section for a detailed description of these sections.
Data
The first section of a structure page contains basic information about the macromolecule. This includes the title, author, deposition date and the sequence for each unique chain. Where possible, sequences are linked to their appropriate entries in UniProt or GenBank. The data in this section are obtained directly from the PDB and is automatically updated when the underlying data are changed. These structured data allow for searching and navigation of the archive just like any other web-based database.
User comments
Below the static data are the user editable section for community annotation. The user can create or update annotations using the same wiki syntax as Wikipedia or by using a simple form. The semi-structured approach of PDBWiki allows free text comments without restrictions to a particular format, but provides a system for classifying annotations in a hierarchical way (Table 1). For example, the user can tag a comment with the category ‘secondary structure annotation error’. This category is used to mark structures that have mis-assigned secondary structure elements. Subsequently, this label can be used as a filter to find or exclude structures with this annotation.
Part of the hierarchical category system for the pages in PDBWiki (for an up to date list, see: http://pdbwiki.org/index.php/Category:PDB_entry_annotation)
| Category | No. of PDB entries |
|---|---|
| Biological or biochemical detail: annotations with biological significance | – |
| Splice variant | 12 |
| – | 9 |
| Error report: technical errors related to the PDB file | – |
| Format Error | 13 |
| Format in Consistency | 11 |
| Cα only structure | 6 |
| Biounit error | 6 |
| Annotation error | 3 |
| Data deposition error | 3 |
| Experimental error | 3 |
| Related work: related articles and resources. | – |
| – | 2 |
| External resource: databases, websites, movies, etc. | – |
| Movie | 4 |
| General comment: anything that does not fit in any other category | – |
| – | 6 |
The categories shown are those used to classify the ‘user comments’ that have been added to the entries in the PDB. The category system is handled by the MediaWiki software, and is therefore fully user editable.
Links
The third section contains links to external sources of information about the structure. The links are grouped into four subsections: databases, visualization tools, analysis tools and quarternary structure (for websites providing information about the protein’s likely quarternary structure). Wherever possible, the links directly point to the relevant data pages or analysis results for the currently viewed structure. In contrast to similar link collections in databases, such as PDBSum or OCA, in PDBWiki this section is fully user editable. If the user feels that a particular analysis tool is missing she/he can simply add it to the list. Similarly, instead of relying on a particular visualization method chosen by the authors, the user can add a favorite visualization tool and have it available for every structure page visited. Many of the main biomolecular structure web sites carry at the moment reciprocal links back to PDBWiki. Currently these are: RCSB PDB, JenaLib, CSA and PDBSum.
Quaternary structure was regarded as important enough to deserve its own section in the external resource list. For example, novice users of PDB structures are often not aware that the coordinates of crystal structures generally represent an asymmetric unit rather than the biological assembly, and even for experts it is often not clear which biological unit is correct (24). The quaternary structure subsection contains links to various resources with information about the putative biological unit, giving users easy access to this kind of information.
Use cases
PDBWiki provides broadly different functionality to several different target audiences, such as:
Bioinformaticians
Improved navigation of PDB contents by standard categories and customized reports.
A collection of links to PDB-related databases and tools kept up-to-date by PDBWiki administrators and the user community.
A central resource for tracking technical problems with individual structures that are relevant for bioinformatics analyses.
(Structural) Biologists and Biochemists
A convenient interface for looking up basic information about PDB structures with additional annotation from the community.
A forum for discussion about molecular structures.
Learning about problems with the data quality of individual PDB entries (see for example, user annotations for entry 2hr0).
Discovering additional information submitted by original authors of a structure (see for example, user annotations for entry 2cme).
Learning about the studies that a particular structure has been used in (see for example, user annotations for entry 1a32).
Crystallographers
Raising awareness of publications demonstrating important work to a wider community.
Keeping track of how published structures are being used.
Publicizing information about structures that do not fit into the standard database format.
Navigation, querying, and reporting
To help browsing through the structures in the PDB, PDBWiki provides navigational categories that group together structures by name, functional classification, experimental method, host organism, enzyme classification and deposition year. These categories are kept synchronized with those in the PDB. In PDBWiki, the categories to which a structure belongs appear at the bottom of every structure page. Clicking on a category takes the user to the category page, where all the structures in the category are listed. In addition, structures are categorized by the type of user annotation that has been added. For example all structures with user annotations related to biological units can be found in the category ‘Biounit discussion’. Further categories are listed in Table 1.
In addition to free text searches, the user can create custom reports similar to database queries. Both the selection criteria and the displayed information about the structures can be customized. Reports are generated based on combinations of categories or specific lists of protein structures. The result is a wiki page that can be downloaded for further analysis. Figure 2 shows a custom report for proteins in the taxonomic category Escherichia coli that are functionally classified as antibiotics. The report includes the PDB code, title, resolution and a thumbnail. An advantage of these reports is that they can be embedded in any wiki page while being always automatically up to date, since they are based on the current state of the data in the wiki. A detailed tutorial of how to create custom reports including examples can be found in the website (http://pdbwiki.org/index.php/Structure_report).

A custom structure report. The report shows data from proteins in E. coli that are classified as antibiotics. The report was generated from a combination of categories and displays a selection of the data available for each structure. A detailed tutorial of how to create custom reports including examples can be found in the website (http://pdbwiki.org/index.php/Structure_report).
Unlike the typical search results pages common to most web-based databases, custom reports in PDBWiki are saved as distinct pages in the wiki. In this way, the results of a specific report can be easily linked, shared or discussed. For example, a hand curated list of structures could be created on PDBWiki and used in a custom report. A link to the report could then be posted on a mailing list for discussion. Additionally, reports created using categories will remain up-to-date as new structures in the categories are released, updated or obsoleted.
Added value provided by PDBWiki
In software engineering, bug-tracking systems have proven to be essential tools for quality management. Despite best efforts during development, effective quality control can only be achieved by contributions from the user community. Such systems are typically implemented as public databases, where users can submit problem reports and feature requests. PDBWiki has been designed to provide similar functionality for the PDB community.
Having a central community resource with quality-related information about protein structures can help bioinformaticians and structural biologists to choose proteins for experiments and to avoid pitfalls with well-known ‘problem-structures’. To this end, PDBWiki provides comment features in combination with categories for labeling comments related to quality issues (Table 1), as well as easy access to external analysis tools (Figure 1).
To make full use of the collaborative effort, there should be a way of integrating relevant user submissions back to the original database. We think that this should be carefully done by expert curators. The semi-structured nature of PDBWiki user comments can help the curators of the PDB to monitor new annotations and possibly incorporating them into the original data.
To provide an additional resource for the structural biology community, we have summarized over 2 years worth of posts to a popular community mailing list http://lists.sdsc.edu/mailman/listinfo.cgi/pdb-l. These posts have been summarised in the form of a ‘Frequently Asked Questions’ (FAQ) page. Specifically, we wanted to provide a useful resource that would attract users to the site. The FAQ has been visited over 5000 times and edited 15 times by users originally unknown to the present authors. The FAQ contains over 30 categorized questions, and like the rest of PDBWiki, is free for anyone to edit. One indication of the community value added by this resource is that performing a Google keyword search for the terms ‘PDB’ and ‘FAQ’ returns the PDBWiki FAQ page as the first hit.
Usage
Since November 2007, there have been over 50 000 visits to PDBWiki. Excluding the present authors, there are 11 registered, contributing users and another 20 registered but inactive users. In total, we have collected over 100 user comments, each providing additional information about one of the structures in the PDB. All user comments are assigned to one of several broad categories. The most frequently used categories on the site are: format errors (11), format inconsistencies (16), Cα only structures (10) and errors in the proposed biological unit (7). A number of these reported issues have been resolved as part of the ongoing remediation efforts of the PDB. These cases are additionally categorized as ‘solved’ (4).
One example of an interesting user annotation is that of PDB entry 2hr0. The structure was annotated in December 2008, indicating that a study published the year before in the jounal Nature had deemed it incorrect (25). In December 2009, it was announced by the University of Alabama that the structure was one of a number of fabricated crystal structures http://main.uab.edu/Sites/reporter/articles/71570. PDB has since retracted one of them (1bef). This kind of information is invaluable for structural biologists or bioinformaticians using that structure in their studies.
Further examples of user annotations exemplifying the kinds of comments being submitted and the added value provided by such annotations can be found in the wiki (http://pdbwiki.org/index.php/Example_annotations).
One of the most commonly edited sections of the wiki is the collection of user-contributed resources. This section is included on every structure page and provides specific cross-references to resources for the structure (as described above). To date, there have been 13 user edits to this section. Including additional resources that were added by request, the number of cross-references has grown from 17 originally to 39 to date. Resources that have been added include STRAP (26), MolProbity (27), TOPSAN (28) and Polyview 3D (29).
Although the above counts of user and edits may seem low, they are encouraging relative to similar projects where user contributions can be rare. The number of contributions to PDBWiki is continuing to grow, and we believe will continue to do so as the site becomes increasingly well known. We expect to see a positive feedback effect on the amount of user contribution, as increasing contributions will in turn increase the value of the service the site provides.
Discussion
Community data curation promises to be a solution to the problem of coping with the increasing size and complexity of biological data. The challenge is to make use of the ‘wisdom of the many’ without compromising the advantages of central, trusted and manually curated databases. In Wikipedia, most edits are small and come from many different users, yet this activity accounts for the majority of the content added to the site. However, this situation relies on a well-established infrastructure on which the community can build (30).
Here, we present an easy-to-use system that combines the data from the PDB with community annotation features. The design, based on the well-known MediaWiki software, keeps the barrier for user contribution low. We address the issues of data integrity and trust by clearly separating the original database content from the user annotations. To organize the user-contributed data, we provide a category system that will help curators to incorporate community suggestions back into the original database.
PDBWiki shares many similarities with Wikipedia. Although the common user interface and reuse of open source code have clear benefits (see the ‘Methods’ section), the value of PDBWiki lies in its differences from Wikipedia. Specifically, PDBWiki combines semi-structured comments with data from an external, authoritative database.
PDBWiki was always envisioned as a community project. All the source code for the site is freely available in an SVN repository svn://bioinformatics.org/svnroot/pdbwiki and developer discussion is publicly archived on the pdbwiki-devel mailing list http://www.bioinformatics.org/pipermail/pdbwiki-devel. The wiki includes a page dedicated to ‘feature requests’ http://pdbwiki.org/index.php/Development, where users can add and review suggestions for new features. We plan to keep working on the website, improving the existing functionality and implementing new ideas.
Related work
Similar projects to PDBWiki have recently appeared. Proteopedia (19) is a wiki-based system for the dissemination of knowledge about macromolecular structures to a broad scientific audience. As with PDBWiki, Proteopedia consists of one page per PDB entry that can be edited by users to contribute information about the particular structure. A key feature of Proteopedia is the Scene Authoring Tool, that can be used to easily create so-called molecular scenes that contribute by illustrating specific points about the structures. They focus on being an educational resource and dissemination tool for structural biology, while in the current project, our main focus is on annotation for the ‘end users’ of the structural data. For example, user comments in PDBWiki are linked to entries via categories. Proteopedia, in contrast, has longer, more free ranging educational articles that span several entries.
Although the initial motivation for PDBWiki and Proteopedia was similar, it has become apparent that the two projects have developed in different directions. In broad terms, PDBWiki functions as a ‘community discussion forum’ and Proteopedia as a ‘community education portal’. In future we expect this division to continue, with PDBWiki tending towards integration with the PDB and Proteopedia tending towards integration with Wikipedia.
The Open Protein Structure Annotation Network (TOPSAN) (28) can be viewed as another similar project. TOPSAN stems from the Protein Structure Initiative (a Structural Genomics project) and was created with the intention of enriching the knowledge of poorly annotated protein structures solved by Structural Genomics projects. Structures from both the PDB and the Structural Genomics projects are annotated using a wiki-style system. Thus, the key difference from PDBWiki is the scope: targets from Structural Genomics versus the whole of the PDB.
There exists a number of other community-based biological curation efforts, for example, Human Proteinpedia (23), Wikiproteins (18) and Gene Wiki (16). Although they are all based on the idea of user-contributed annotations they differ significantly in their goals and scopes from the present project.
Community annotation
The life sciences community is still in an early stage of experimenting with different approaches to community annotation. Some databases have already started to provide user feedback systems into their interfaces (31, 32). Other projects seek to build on the established authority and user base of Wikipedia by creating sub-projects within Wikipedia itself (16).
The size of the user base and the amount of content varies for the different projects. The question arises as to why some projects attract more participating users than others. We can not give a final answer to this question, but we have observed that for collaborative projects such as wikis to be successful, there are two key factors. (i) The project should be focused, such that the potential benefit of the collaborative effort is apparent for the target audience. (ii) The project should provide an immediate value for the users to encourage them to visit and eventually contribute.
There are clear examples of successful scientific wiki projects. To mention just two examples, WikiPathways (17) currently contains 1269 annotated biological pathways, maintained by 810 users, and the Molecular and Cellular Biology project within Wikipedia maintains nearly 20 000 articles with 260 registered participants.
The success of these projects shows that there are enough scientists who are willing to contribute to collaborative efforts. These projects are able to sustain contribution, even without traditional mechanisms of reward.
Conclusion
Here, we present a wiki system that allows community annotation of PDB structures. Unlike a database, PDBWiki allows free text comments and unlike traditional wikis, it provides structured classification of the contents. So far, our focus has been on technical comments for users working with PDB structures but the system is not restricted to this use.
The positive feedback we have received about PDBWiki and the growing number of users and annotations are encouraging. We continue to make the site easier to use and to provide value in the form of content to attract more users and contributors. The forms extension we developed, allows users to enter comments with minimal effort through a webform without having to know wiki syntax as in other wikis. This extension also allows easy semantic classification of the submitted comments.
We believe that ultimately, the development of new software, specifically dedicated to community annotation of biological databases combined with the authority of the established resources, such as the PDB, will provide the impetus to achieve the full potential of community annotation.
Many newly developed databases already incorporate explicit mechanisms for user contribution, beyond simple email feedback (32). This shows that wikis or some variation of the wiki idea will play an important role in computational biology in the future. In the present work, we not only demonstrate what can be done in this regard with current technology but also present a valuable resource for the structural community that provides unique functionality and unique user-submitted content that can currently not be found anywhere else.
Funding
Funding for open access charge: Otto-Warburg-Laboratory, Max Planck Institute for Molecular Genetics, Berlin, Germany.
Conflict of interest. None declared.
Acknowledgements
The article was collaboratively written using the MediaWiki software package http://www.mediawiki.org. The authors would like to thank Maryana Bhak for help proofreading and correcting a draft of the article. The authors would also like to acknowledge the Max Planck Institute for Molecular Genetics for continued support.
References
Author notes
Present addresses: Jose M. Duarte, Paul Scherrer Institut, OFLC/110, 5232 Villigen PSI, Switzerland. Dan M. Bolser, School of Life Sciences Research, University of Dundee, Dundee, DD1 5EH, UK.

{kind=link}
{kind=link}
Comments
The suggestion to merge PDBWiki [1] and Proteopedia [2] has come up several times during review, and in informal discussion of the PDBWiki project. We agree that it is desirable to have a central resource with user contributed annotation for PDB structures. After careful consideration, however, we have decided that for the moment it is preferable to keep the two projects independent, and we would like to explain our reasons for this decision. Currently, PDBWiki and Proteopedia are the only two active projects that provide community enriched information for the whole of the PDB. The two wikis were independently developed at a time when it was apparent that there was a need for a community annotation resource for protein structures. The availability and popularity of the MediaWiki platform [3] provided the technical means to implement such a system. Although the initial motivation for the two projects may have been similar, now, over two years later, it has become apparent that the two projects have developed in different directions.
Proteopedia is unique and outstanding in the way it allows the integration of interactive molecular visualization into user created articles. There is an active community writing and editing informative articles about featured structures. In this sense it is similar to the Protein of the month feature on the RSCB website with the additional benefit of interactive visualization. These articles describe a particular protein, protein complex or protein family but are rarely limited to a particular PDB entry.
A PDB entry, even though often regarded as 'a structure' or 'a protein' is really the description and the results of a structure determination experiment. What we found when working with PDB coordinates is that individual entries are often idiosyncratic. Questions about particular entries are often raised on the pdb-l mailing list [4], which is a useful community discussion forum. This is where we feel that PDBWiki provides its unique 'added value'. It allows users to provide additional, structured information about particular PDB entries. PDBWiki is strictly built around the concept of PDB entry. In accordance with this principle, PDBWiki provides specific features for searching, categorizing, commenting and reporting PDB entries and their respective user annotations. After initial experiments with Wikipedia style free-text editing, we found that users rarely wanted to create long articles, preferring to leave short comments, another distinctive feature between Proteopedia and PDBWiki.
What we have chosen for now, instead of simply adding all contents of one project to the other, is to cross link the contents as much as possible. We do this by proving a link to Proteopedia for every PDB entry in PDBWiki. In this way, the complementary information in the two sites is accessible by a single click. At the same time, the two sites can be developed independently, focusing on their respective strengths.
Even the names of the two project are not arbitrarily chosen and are indicative of their different focus. Proteopedia is an encyclopaedia of proteins while PDBWiki is a resource directly linked to the PDB. The logical consequence of this distinction is that PDBWiki should eventually form a part of the PDB. Currently, however, the PDB is focused on its role as a primary database, and does not provide the same functionality as PDBWiki.
We created PDBWiki out of our need for a resource that provides structured information about the specific issues related working with the coordinates in the PDB. We would be happy if, in the future, the RCSB would decide to take over this responsibility. Currently however, the community is being served better with PDBWiki than with the alternatives that are available.
References
Conflict of Interest:
None declared