





Abstract
Bread wheat is one of the most important crops worldwide. With the release of the complete wheat reference genome and the development of next-generation sequencing technology, a mass of genomic data from bread wheat and its progenitors has been yield and has provided genomic resources for wheat genetics research. To conveniently and effectively access and use these data, we established Wheat Genome Variation Database, an integrated web-database including genomic variations from whole-genome resequencing and exome-capture data for bread wheat and its progenitors, as well as selective signatures during the process of wheat domestication and improvement. In this version, WGVD contains 7 346 814 single nucleotide polymorphisms (SNPs) and 1 044 400 indels focusing on genic regions and upstream or downstream regions. We provide allele frequency distribution patterns of these variations for 5 ploidy wheat groups or 17 worldwide bread wheat groups, the annotation of the variant types and the genotypes of all individuals for 2 versions of bread wheat reference genome (IWGSC RefSeq v1.0 and IWGSC RefSeq v2.0). Selective footprints for Aegilops tauschii, wild emmer, domesticated emmer, bread wheat landrace and bread wheat variety are evaluated with two statistical tests (FST and Pi) based on SNPs from whole-genome resequencing data. In addition, we provide the Genome Browser to visualize the genomic variations, the selective footprints, the genotype patterns and the read coverage depth, and the alignment tool Blast to search the homologous regions between sequences. All of these features of WGVD will promote wheat functional studies and wheat breeding.
Bread wheat (Triticum aestivum) is the most widely grown food crop in the world and provides the major source of the calories and protein humans consumed. It has an allohexaploid genome that includes three subgenomes (AABBDD) (1). Its origin is ascribed to two evolutionary events; first, the formation of tetraploid domesticated emmer (Triticum dicoccum, AABB) from domesticating tetraploid wild emmer (Triticum dicoccoides, AABB), and second, the evolution of hexaploid bread wheat by hybridization of tetraploid domesticated emmer with diploid Aegilops tauschii (Ae. tauschii, DD) (2, 3). During the process of polyploidization, domestication, improvement and dissemination, wheat underwent natural and artificial selection for yield, quality and adapting the different eco-geographic habitats (4–7), which led to the formation of diverse populations. The release of the complete bread wheat reference genome (8) and the decreasing costs of sequencing have resulted in rapidly accumulating genome variation data and analyzing selective signatures. As one of the most important types of molecular variation, single nucleotide polymorphism (SNP) is broadly distributed in the genome, which makes it a powerful marker for wheat population genetics study, particularly for the selection regions analysis, and the gene loci identification associated with desired traits (9, 10). Therefore, establishing a comprehensive web-database, which integrates the genomic variations and displays the selective footprints from populations, is vital for wheat genomics research.
Here, we established a database WGVD containing the genome variations and the selective signatures focusing on wheat domestication and improvement from five groups: wild emmer, domesticated emmer, Ae. tauschii, bread wheat landrace and bread wheat variety. In the current version, we have collected high-resolution whole-genome resequencing data and exome sequencing data from 968 bread wheat and its progenitors (11–13). A total of 7 346 814 SNPs and 1 044 400 indels concentrating on genic regions and upstream or downstream regions have been included in WGVD. Furthermore, we have implemented two statistical methods, nucleotide diversity (Pi) (14) and Weir and Cockerham’s FST (15), to calculate the selective scores based on the 93 whole-genome resequencing wheat accessions. WGVD would be a valuable platform for the global research community to promote the wheat-related studies.
Database structure and content
The WGVD contains SNPs, indels, signals of selection, genome browser and alignment tool (Blast) for wheat. Figure 1 shows the analysis pipeline used to build the database. The detailed description is provided in the following sections.
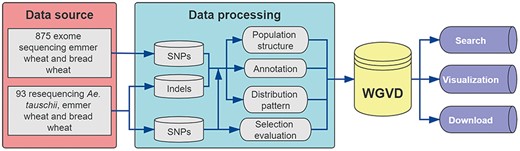
Data sources and analysis pipeline used to build the database.
Sample information
Our database brings together the published wheat genome sequence data from 1 whole-genome resequencing dataset of 93 wheat accessions including 5 Ae. tauschii, 20 wild emmer, 5 domesticated emmer, 29 bread wheat landraces and 34 bread wheat varieties, and two exome sequencing datasets of 875 wheat accessions including 33 wild emmer, 35 domesticated emmer and 807 bread wheat (11, 12) (Figure 2). Overall, genomic information from 968 bread wheat and its progenitors comprising 5 diploid Ae. tauschii (AE), 53 tetraploid wild emmer wheat (WE), 40 tetraploid domesticated emmer wheat (DE) and 870 hexaploid bread wheat is obtained and analyzed. Bread wheat contains 315 landraces and 471 varieties. According to the geographic origin, tetraploid wild emmer wheat is separated into three groups: Southern Levant 1 (WE Sorth1), Southern Levant 2 (WE Sorth2) and Northern Levant (WE North), including 7, 30 and 16 samples, respectively. Likewise, except for 7 accessions of unknown geographic origin, hexaploid bread wheat contains 9 groups: 87 African wheat (Africa), 122 Western European wheat (EurWest), 93 Eastern European wheat (EurEast), 201 Asian wheat (Asia), 90 wheat from Former Soviet Union (Former SU), 79 North American wheat (NorthAm), 74 South American wheat (SouthAm), 47 Central American wheat (CentAm) and 70 Oceanian wheat (Oceania). Geographical origins and other detailed information for all samples can be obtained from the homepage and ‘Sample Table’ page in WGVD.
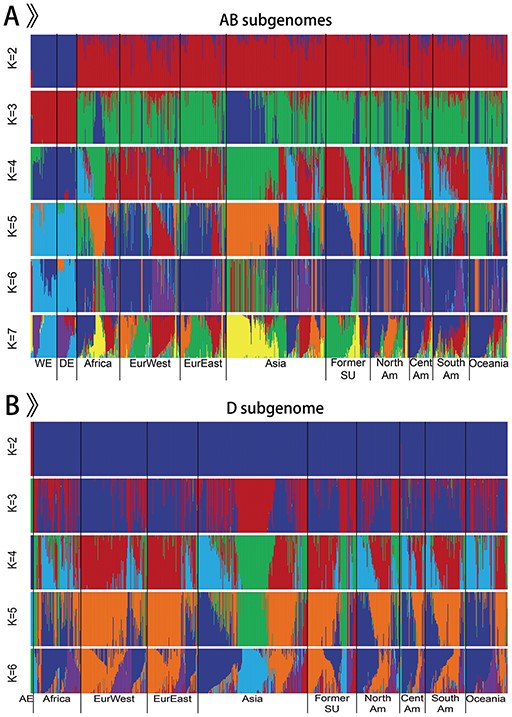
Population structure of 968 accessions.
SNPs and indels information
In addition to the SNP and indel dataset generated by Cheng et al. (13), we have downloaded the published SNP dataset from two other studies (11, 12). Due to the different reference genomes used for calling SNPs from some emmer wheat (11), we selected the 100 bp flanking sequences of each SNP in the reference genome of emmer to align onto the bread wheat reference genome IWGSC RefSeq v1.0 using BLAST. The parameters, alignment coverage > 50% and identities > 90%, were used for defining a blast hit. The SNPs and indels (1–50 bp) located in the genic regions and the flanking segment (3 kb upstream or downstream regions) were selected from the 93 resequencing data (13). Finally, we integrated all the processed SNPs and indels, and obtained a total of 7 346 814 SNPs and 1 044 400 indels. PLINK (16) was used to calculate minor allele frequency (MAF) for all wheat and allele frequencies for each ploidy wheat group and the worldwide bread wheat group. The snpEff (version 4.3p) software was used to annotate variant effects of SNPs and indels (17). Given that two versions of bread wheat genome (IWGSC RefSeq v1.0 and IWGSC RefSeq v2.0), we have converted each SNP and indel on IWGSC RefSeq v1.0 by aligning the flanking sequences onto IWGSC RefSeq v2.0 using BLAST with the parameters ‘alignment coverage > 99% and identities > 99%’.
Statistical terms for selective signatures in the WGVD.
| Statistical term | Abbreviation | Population 1 | Population 2 | Windows |
|---|---|---|---|---|
| Nucleotide diversity | Pi | Ae. tauschii (AE) | 100k | |
| Cockerham & Weir Fst | FST | Wild emmer (WE) | Other four groups | 100k |
| Domesticated emmer (DE) | ||||
| Landrace | ||||
| Variety |
Population structure
We only retained the integrated SNPs with a maximum missing rate < 0.9 for population structure analysis. The software ADMIXTURE (version 1.3.0) was used to analyze the population structure of all accessions (18). ADMIXTURE was run from K = 2 to K = 7 with 20 bootstrap replicates on AB subgenomes of 963 individuals (Figure 2A) and from K = 2 to K = 6 with 20 bootstrap replicates on D subgenome of 875 individuals (Figure 2B). The results showed that the separation of emmer wheat and Ae. tauschii from bread wheat, as well as the high-level interpopulation admixture of bread wheat, which were consistent with previous findings (4, 12, 13, 19). To better illustrate the population structure of hexaploid bread wheat and tetraploid emmer wheat, and to reduce the influence of high repeat of bread wheat genome, particularly in the intergenic regions, we selected the SNPs in the genic regions to construct NJ trees with PHYLIP (version 3.68) (20) for 870 bread wheat and 93 emmer wheat, respectively. These trees were visualized with Interactive Tree of Life (21). Except for the difference caused by the sequencing methods, the result was in accordance with previous depictions (12, 13).
Selection evaluation
WGVD provides selective signatures from five groups including Ae. tauschii, wild emmer, domesticated emmer, bread wheat landrace and bread wheat variety. Due to the higher density and broader distribution of SNPs from the whole-genome resequencing data than from the exome sequencing data, we selected the whole-genome SNPs from 93 wheat accessions to evaluate selective footprints with Cockerham and Weir Fst (FST), and nucleotide diversity (Pi) (13) (Table 1).
Database implementation
The WGVD was built with Apache, PHP, MySQL, JavaScript and HTML. The processing of variations (SNPs/indels) and selection scores were processed with Perl scripts. And the corresponding data were deposited in the MySQL database. The implementation of data search, visualization and download were used with HTML5 and JavaScript. Moreover, ViroBLAST and the UCSC Genome Browser (Gbrowse) were introduced into the WGVD (22, 23).
Usage
WGVD can be accessed through a user-friendly interface. We provide the ‘Manual’ in ‘Documentation’ page for users to access the database. Generally, WGVD has four main functionalities: variation search, genomic selection search, genome browser and alignment search tool (BLAST).
Variation search
We provide two versions of bread wheat genome (IWGSC RefSeq v1.0 and IWGSC RefSeq v2.0) for users to choose (Figure 3A). Users can get detailed SNPs or indels information by a given gene name or genomic location in the reference genome (Figure 3B). In addition, users can set the parameters, MAF and consequence type to search for variations of interest in a more efficient and faster manner (Figure 3C).

Screenshots of a SNP data search.
The retrieved results are shown with an interactive table and graph. Users can get details of SNPs and indels in 5 ploidy wheat groups or 17 worldwide bread wheat groups (Figure 4A, B, C), such as the variant position, allele, MAF, variant type and the distribution pattern of allele frequency. By clicking the group name, users can also obtain the information on individual genotypes (Figure 4D).

The result display by searching a SNP data for example.
Genomic selection search
Users can get the selective scores by choosing a given gene name or genomic location, one of the statistical methods (Pi or FST) and one of the wheat groups (Ae. tauschii, wild emmer, domesticated emmer, bread wheat landrace or bread wheat variety) (Table 1 and Figure 5A). Table 1 displays the results including a selective region and the corresponding overlapping genes (Figure 5B). While clicking the ‘show’ button, users can obtain the selective signatures showing with Manhattan plot and the common graphic, in which the target gene or region is highlighted with red color. To prove the function of our database, we retrieved TraesCS5A01G473800 (Figure 5A) identified as gene Q controlling free threshing (24) by BLASTn. The result displayed a significant selection signal between wild emmer and bread wheat landrace (Figure 5B), which accorded with previous reports (12, 13, 24).
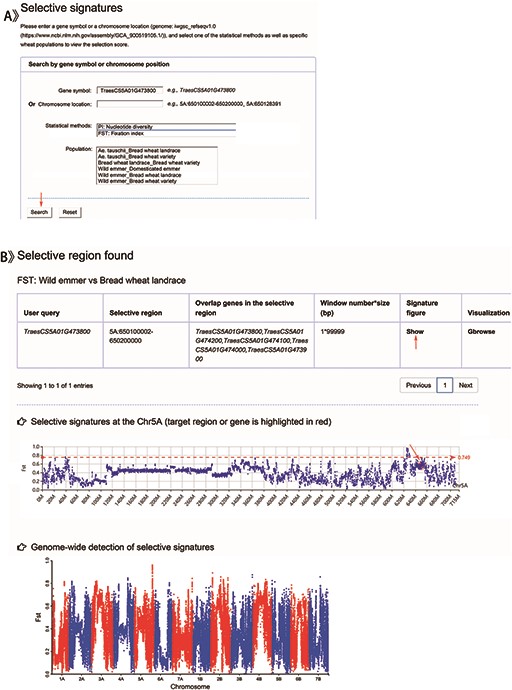
Screenshots of a search for genomic selection data and the result display for example.
Genome browser
A total of 19 and 6 tracks have been provided for the reference genome IWGSC RefSeq v1.0 and IWGSC RefSeq v2.0, respectively. By retrieving a special gene name or chromosome location, users can view SNPs, indels and signals of selection as a whole. Due to the large size of whole-genome resequencing BAM files (e.g. ∼50 GB for each file), the read coverage depth of the genome was computed using bamCoverage from deepTools2 (25) with the option ‘--binSize 100’ and shown in ‘Reads coverage’ track, which helps to visualize the distribution of genes for each accession. For example, TraesCS5D01G548500, the homologous gene of disease resistance protein RPP13 in Brachypodium distachyon, is absent in landrace C21, C23 and C29 as indicated by the few reads alignment (Figure 6). Most notably, the genotype patterns of 93 wheat accessions are shown in ‘Genotype patterns’ track with homozygous reference in gray, heterozygous variant in yellow and homozygous variant in green, which would allow users to observe haplotype blocks and different haplotypes. Figure 7 displays a region on chromosome 4A including TraesCS4A01G132700 identified as ABCT gene (26). The genotype pattern in this region obviously displays 3 distinct haplotypes, in which wild emmer W7 shares the same haplotype with 14 landrace accessions. Gene TraesCS2B01G534200 annotated as being an NADPH-cytochrome P450 reductase, which co-localized with the QTLs related with resistance to leaf rust (27), shows two different haplotypes among bread wheat (Figure 8). Gene TraesCS4D01G347800 is the homologous gene of FPF1 in Arabidopsis thaliana controlling flower development, in which Asian landrace C21, C27 and four Ae. tauschii accessions are grouped into one haplotype (Figure 9).
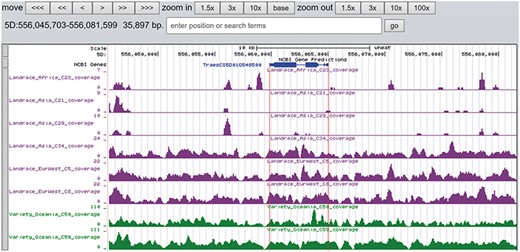
The read coverage depth on the region of gene TraesCS5D01G548500 in eight bread wheat accessions. The gene is absent in three landrace (C21, C23 and C29) as indicated by the few reads alignment, while it is present in the other five accessions.
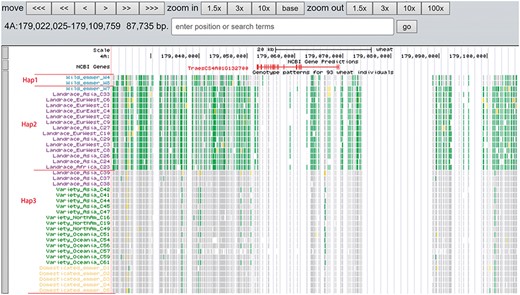
Three haplotypes (Hap1, Hap2 and Hap3) for gene TraesCS4A01G132700 region among wild emmer, domesticated emmer, landrace and variety based on the genotype pattern with homozygous reference in gray, heterozygous variant in yellow and homozygous variant in green.
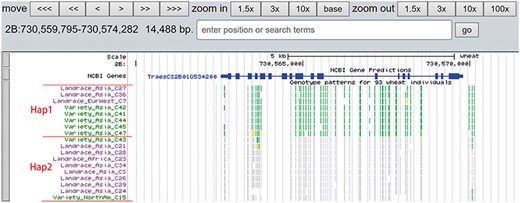
Two haplotypes (Hap1 and Hap2) for gene TraesCS2B01G534200 region among bread wheat based on the genotype pattern with homozygous reference in gray, heterozygous variant in yellow and homozygous variant in green.
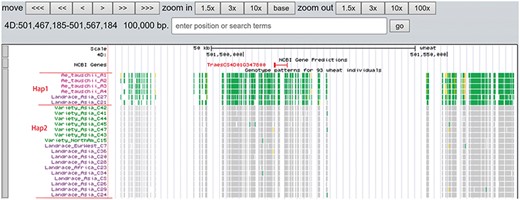
Two haplotypes (Hap1 and Hap2) for gene TraesCS4D01G347800 region among Ae. tauschii, landrace and variety based on the genotype pattern with homozygous reference in gray, heterozygous variant in yellow and homozygous variant in green.
Alignment search tool (BLAST)
Users can input sequences in fasta format to search the homologous regions in the reference genome IWGSC RefSeq v1.0 and IWGSC RefSeq v2.0.
Discussion
WGVD is an open-source web-based database aggregating the SNPs collected from 968 bread wheat and its progenitors, indels, as well as selective signatures during the process of wheat domestication and improvement based on the whole-genome SNPs from 93 wheat individuals. Compared to the previous databases including wheat variations, such as GrainGenes (28), dbSNP (29), Wheat@URGI (30) and Wheat-SnpHub (31), WGVD provides the allele frequency distribution pattern of each SNP or indel in diverse groups based on all collected samples, the individual genotypes, the read coverage depth and the detailed sample information on individuals, which could improve the utilization of data and contribute to the population genetic analysis. Moreover, we provide selection scores for five groups of Ae. tauschii, wild emmer, domesticated emmer, bread wheat landrace and bread wheat variety by using two statistical terms This resource facilitates users to identify the selection loci or genes associated with phenotypic changes and study the corresponding mechanisms Users can also download sample list, variation data and selection signal data from WGVD for other studies of interest. We believe that our database facilitates wheat evolutionary studies and functional genes mining.
The database will be updated regularly with new released resequencing data of bread wheat and its progenitors. We will provide uploading functionality for users to submit resequencing data or SNP list directly to WGVD. We will also provide other genetic statistical methods, such as Hp (32), iHS (33), XP-EHH (34) and XP-CLR (35) and recombination maps to WGVD, as well as selective signatures for wheat of different geographical origins. Furthermore, structural variations of wheat genomes will be integrated into the database.
Authors’ contributions
Yu Jiang and Zhensheng Kang conceived of the project and designed the research. Jierong Wang drafted the manuscript. Weiwei Fu and Jing Zhao revised the manuscript. Jierong Wang and Hong Cheng performed the data analysis. Weiwei Fu, Rui Wang and Dexiang Hu wrote the source code for the WGVD.
Acknowledgements
We thank the contributors of the wheat genomic variation datasets. We also thank Dr Qingdong Zeng and Dr Jianhui Wu from Northwest A&F University (China) for their kindly revising the manuscript.
Funding
This work was supported by the National Key Research and Development Program of China [2018YFD0200402, 2018YFD0200408], the China Agriculture Research System [CARS-3] and the Natural Science Basic Research Plan in Shaanxi Province of China [no. 2019JCW-18].
Conflict of interests
None declared.
References
Author notes
† These authors contributed equally to this work.
Citation details: Wang, J., Fu, W., Wang, R. et al. WGVD: an integrated web-database for wheat genome variation and selective signatures. Database (2020) Vol. XXXX: article ID baaa090; 10.1093/database/baaa090

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}